DataGenerator¶
When we work with baangt to perform various tasks, we need to give excel file containing all data as input.
Sometimes this data can be too big and can be a huge headache when one has to type all these manually. To overcome this
issue we had made an application which can generate all possible data combinations by just providing and small excel file
containing all data.
Input File¶
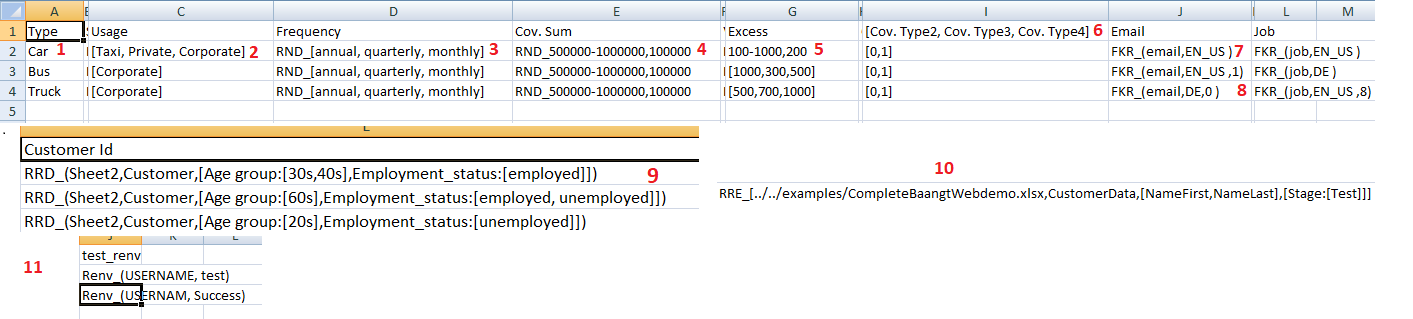
- This image is an example input file. Different types of data types supported are given different number in the above image.
- Is a simple value.
- Is a list of value.
- Is a list of value with
RND_prefix. We will learn more on it further. RND_1,10,2:RND_prefix is also used here but with a range.- Simple range.
- List of header.
FKR_prefix is used here.FKR_prefix is used here with a new integer value 0 in end.RRD_prefix is used here.RRE_prefix is used here.RENV_prefix is used here.
Using these data type we will generate all possible values. Here is a simple example with simple value and value of list.
Example Input:-
vehicle, seats car, [2,4,5] bus, 60
Example Output:-
vehicle, seats car, 2 car, 4 car, 5 bus, 60
As you can see that the output file contains every possible combination of input file. Further you will learn more about Data Types in next section.
Data Type¶
- We will use the reference of above image and assigned number to learn about it in detail.
It is a simple single value.
It is a list of values which will be further used to create all possible combinations as shown in above example. Format = [value1, value2, value3]
Here comes a prefix.
RND_is a prefix which is used when we don’t need to create all possible combinations from a list and have to use any one of the data from the list whenever new data is generated. So it will not increase number as it is not compulsory to use all value.Range is a new data type. It is used when we want to create a list of number with all of them having same gap between them. Format = Starting-Ending,Step Example input = 2-40,4 || Output = [2, 6, 10, 14, 18, 22, 26, 30, 34, 38] As shown in example, instead of writing whole list we can just use Range. In our example range is used with
RND_so after creating this list random function will come into effect.As explained in point 4.
List of header. When there are multiple headers which have same value inside them, then we can simply write a list of header in a single cell. Then the program will consider each value as an individual header and each of them will have the same below data. Example: header1, [header2,header3] value1 , value2 output: header1, header2, header3 value1 , value2 , value2
FKR_is another prefix used to generate fake data. It uses the faker module of python the generate the fake data. format =FKR_``(type, locale) Note:- We use tuple with ``FKR_prefix Example =FKR_(email, EN_US)In our example we used type = email as we want to get fake emails. EN_US is a locale which will make sure that email should be of same words of that language. By default this will create list of 5 fake emails, if you want to change default number of 5 you can add that number in the end of tuple. Example:-FKR_(email, EN_US, 8)Now this will generate list of 8 fake email and on every data any random email would be selected.Now what if we don’t want to create a list of email instead we want new mail for every data generated. For this we can simply use 0 number at the position of list length. Example:-
FKR_(email, EN_US, 0)Now this will generate new email for every data in the output.RRD_is used when we have multiple sheets in a input file and we need to take value which are matching conditions from that sheet. Format:-RRD_(<sheetName>,<TargetData>,[Header1:[Value1],Header2:[Value1,Value2]])orRRD_(<sheetName>,<TargetData>:<HeaderName>,[Header1:[Value1],Header2:[Value1,Value2]])Here sheetName is the name of the sheet where our TargetData is located. A dictionary of TargetData is generated with all the data which are matching from our Header: Value pair. A header with multiple value list is than converted to all possible value as mentioned in above explanation. At last a random value is selected from TargetData dictionary for every output data. If TargetData:HeaderName then the header of the targetdata from the target file will be replaced with HeaderName in
the output file. Same applies in
RRE_prefix.If TargetData =
*then all the values of the matched row will be treated as TargetData. If Header:Value List =[]then the defined TargetData will be collected from every row of the defined sheet. i.e. For all value in matching rowRRD_(sheetName,*,[Header1:[Value1],Header2:[Value1,Value2]])For TargetData from whole SheetRRD_(sheetName,TargetData,[])For all data inside sheetRRD_(sheetName,*,[])If a input sheet has multiple cells usingRRD_prefix with a matching data (=header of excel column) in TargetData then they will be treated as one unit. In the output file there will be only one column of that matching header and while selecting random data only the rows which have same value of that header will be considered. i.e. FirstRRD_cell has value “x” for the header while selected randomly, then the second cell will select data randomly only from the rows which have “x” value for the same header.RRE_is same asRRD_only change is that in rrd we take data from same file and different sheet but, in thisRRE_prefix we can take data from another file. The only change in its structure is that filename comes before sheetname. i.e.RRE_[fileName,sheetName,Targetdata,[key:value]]RENV_prefix is used to get environment varaible from your system. Their might be sometimes when you don’t want to input sensitive data like password, username, etc. directly inside TestRun file or Globals file, at that time this prefix will be very useful and it will get the data from your system environment. Its structure isRENV_(<env_variable>,<default>)here “<env_variable>” holds the place of variable name which contains data and “<default>” holds the default value which is used in case given variable is not present in environment. If “<default>” value is not supplied and given variable is also not present in environment then it will raise an error. e.g.-RENV(USERNAME, My_Pc)Here it will first look for “USERNAME” variable in environment, if it is not present then it will use “My_Pc”
All Data Types Format¶
- Value =
<value> - list of values =
[<value1>,<value2>] - range =
<start>-<end>,<step> - random =
RND_[list] - random from range =
RND_<start>-<end>,<step> - List of header =
[<title1>, <title2>, <title3>] - Faker Prefix =
FKR_(<type>, <locale>, <number_of_data>) - RRD Prefix =
RRD_(<sheetName>,<TargetData>,[<Header1>:[<Value1>],<Header2>:[<Value1>,<Value2>]]) - RRE Prefix =
RRE_(<fileName>,<sheetName>,<TargetData>,[<Header1>:[<Value1>],<Header2>:[<Value1>,<Value2>]]) - RENV Prefix =
RENV_(<env_variable>,<default>)